Joint compilation: Blake, Gao Fei
Lei Fengwang Note: Dr. He Kaiming began his internship with Microsoft Research Institute (MSRA) after graduating from Tsinghua University in 2007. After graduating from the Chinese University of Hong Kong in 2011, he officially joined MSRA and is currently working as a research scientist in the Facebook AI Research (FAIR) laboratory. He has won two CVPR Best Paper Awards (2009 and 2016) as the first author. Among them, the 2016 CVPR best paper is Deep Residual Learning for Image Recognition. Dr. Ming’s tutorial lecture on ICML2016 and related PPT finishing. Compared with academic papers, he described the profound residual learning framework in a simple and easy-going way in the speech PPT, which greatly reduced the difficulty of training deeper neural networks and also significantly improved the accuracy rate.


Deep residual network - making deep learning super deep
ICML 2016 tutorial
He Kaiming - Facebook AI Research (joined in August)

Overview
Introduce
background
From shallow to deep
Deep residual network
From 10 to 100 layers
From 100 to 1000 layers
application
Q & A


Introduction - Deep residual network (Resnet)
"Deep Residual Learning for Image Recognition" CVPR2016
A framework that can be used to train "extremely deep" deep networks
Realize the best performance in the following areas
Image classification
Object detection
Semantic segmentation
and many more
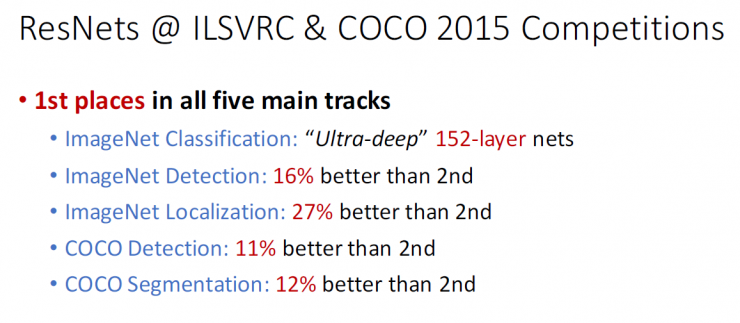
Resnet's performance on ILSVRC and COCO 2015
Scored the first place in the five main task trajectories
ImageNet Classification Task: " Super Deep " 152- layer Network
ImageNet inspection task: 16% more than second place
ImageNet positioning task: 27% over second place
COCO inspection task: 11% more than second place
COCO segmentation task: 12% more than second place
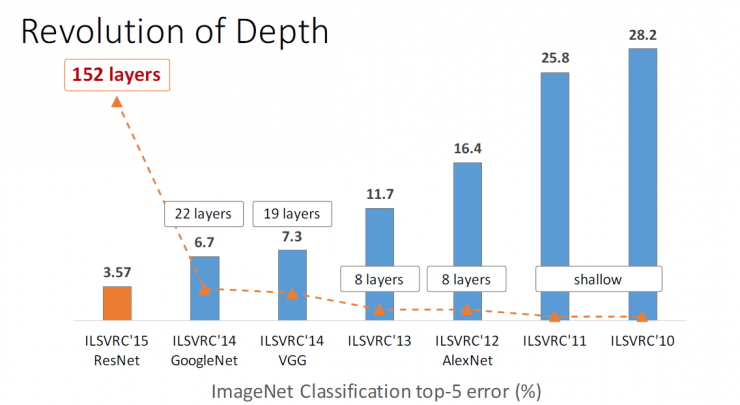
In-depth network revolution (from shallow to deeper levels)
In ILSVRC around 2010, mainly shallow networks, most of which require manual tuning features. In ILSVRC in 2012, there was an 8-layered network, AlexNet, which reduced the error rate by 10%. The VGG and GoogleNet that appeared in ILSVRC 2014 were quite successful. They referred to the hierarchy at 19 layers and 22 layers, respectively, and the error rate was reduced to 7.3 and 6.7. To last year's ILSVRC 2015, our ResNet referred to the 152- tier hierarchy, reducing the error rate to 3.57 .

Deep network revolution
AlexNet, Layer 8 (ILSVRC 2012)
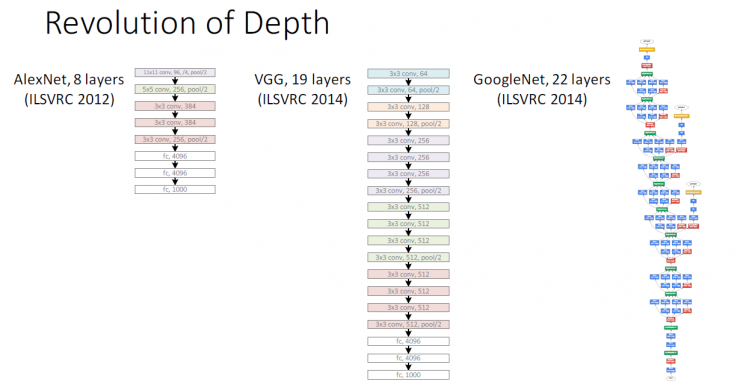
Deep network revolution
AlexNet, Layer 8 (ILSVRC 2012)
VGG, 19th Floor (ILSVRC 2014)
GoogleNet, Level 22 (ILSVRC 2014)

Deep network revolution
AlexNet, Layer 8 (ILSVRC 2012)
VGG, 19th Floor (ILSVRC 2014)
ResNet, Layer 152 (ILSVRC 2015)

Deep network revolution
PASCAL VOC 2007 - Number of layers representing visual recognition
HOG, DPM - Shallow - 34% Object Detection Rate
AlexNet (RCNN) - 8 layers - 58% object detection rate
VGG (RCNN) - 16 layers - 66% object detection rate
ResNet (Faster RCNN) - Layer 101 - 86% object detection rate
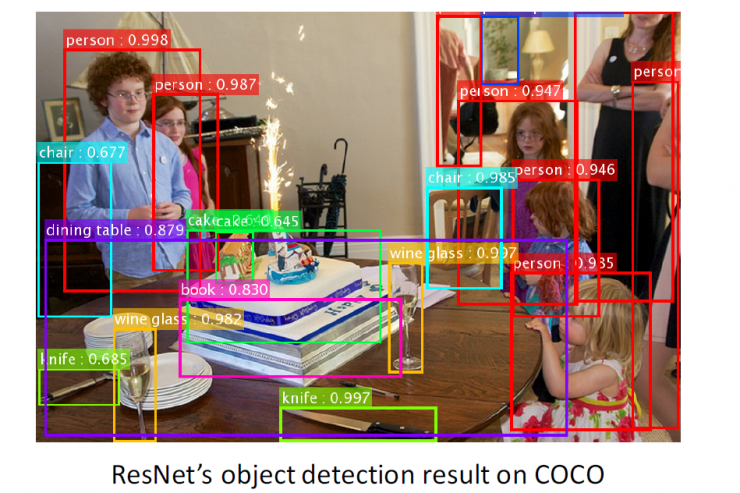
ResNet Object Test Results in COCO Testing
ResNet is simple and easy to learn
Many third-party implementation tools
Facebook AI Research's Torch ResNet
Torch, CIFAR-10, using ResNet-20 to ResNet-110, training code, etc.
Lasagne, CIFAR-10, Using ResNet-32 and ResNet-56, Training Code, etc.
Neon, CIFAR-10, Using pre-trained ResNet-32 to ResNet-110 models, code, etc.
Torch, MNIST, 100 storey
Neon, Place2 (mini), 40 floors
Easy to reproduce results
A series of expansion and follow-up work
More than 200 words quoted within 6 months (posted on arXiv in December 2015)


Step by step
Initialization algorithm
Batch normalization algorithm
Is learning a better network as simple as stacking layers?

Is it just a simple layer stack?
"Plain" Network: Stacked 3x3 Convolutional Networks...
Compared with the 20th floor network, the 56th floor network has higher training error and test error.
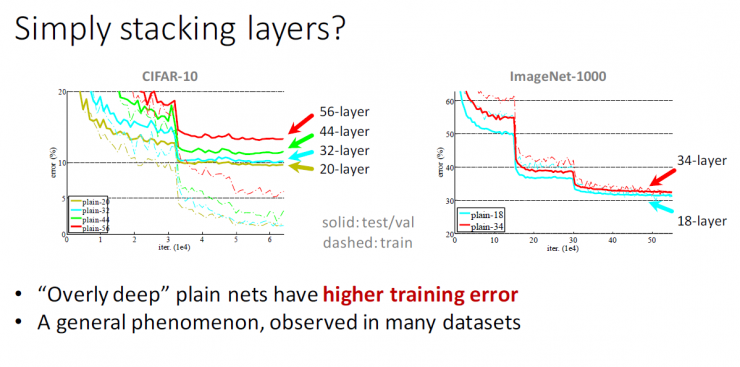
Deep-layered plain network has higher training error
This is a common phenomenon that can be observed in many data sets.
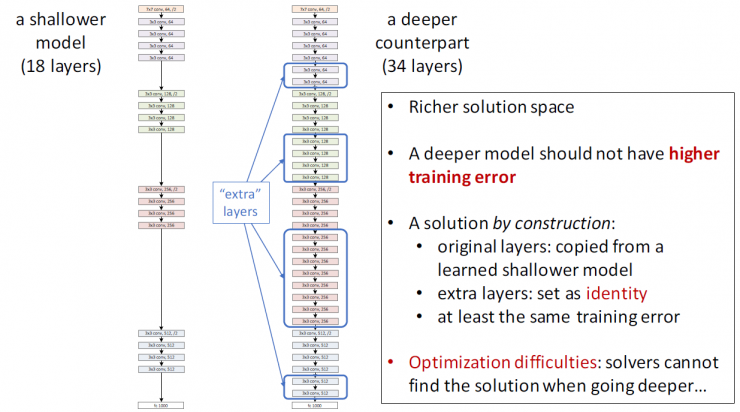
A model with a shallow network layer (18 layers)
Deeper network layer model (34 layers)
Higher resolution space
A deeper network model should not have a higher training error
By building the resulting resolution:
Original layer: copied from a shallower model that has been learned
Additional layer: set to "identity"
At least the same training error
Optimization problems: As the number of network layers deepens, the solver cannot find a solution

Deep residual learning
Plains Network
H(x) is any kind of ideal mapping
It is hoped that the type 2 weights can be fitted with H(x)
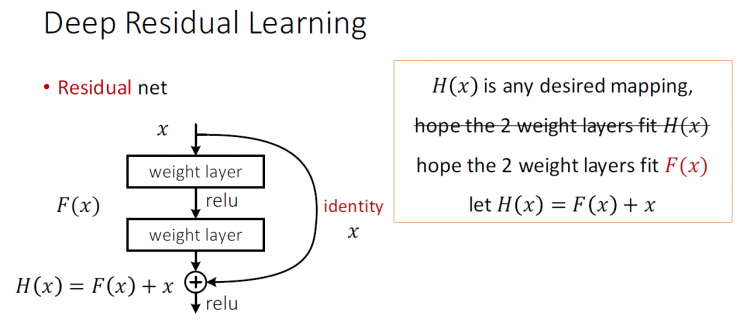
Residual network
H(x) is any kind of ideal mapping
It is hoped that the type 2 weights can be fitted with F(x)
Let H(x) = F(x) + x
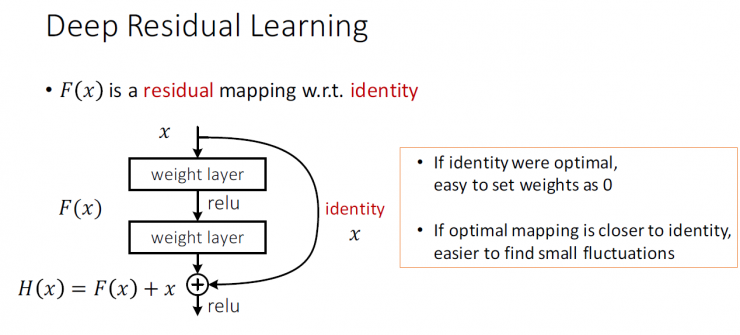
F(x) is a residual map wrt identity
If it is an ideal, it is easy to set the weight to 0
If the idealized map is closer to the identity mapping, it is easier to find small fluctuations

Related research - residual representation
VLAD & Fisher Vector [Jegou et al 2010], [Perronnin et al 2007]
Coded residual vector; powerful shallower representation.
Product Quantification (IVF-ADC) [Jegou et al 2011]
Quantize residual vectors; efficient nearest neighbor search.
Prerequisites for Multi-Layer & Stratification [Briggs, et al 2000], [Szeliski 1990, 2006]
Solve the minor problem of residuals ; efficient PDE solver.

Network "design"
Keep the simplicity of the network
Our basic design scheme (VGG-style)
All 3x3 convolutional layers (almost all)
Space size / 2 => filter x2 (~ the complexity of each layer is the same)
Simple design style; Minimize the design style
Other comments:
No hidden layer fc
No information loss

training
All plain/residual networks are trained from scratch.
All plain/residual networks use Group Normalization (Batch Normalization)
Standardized hyperparameters & enhancements
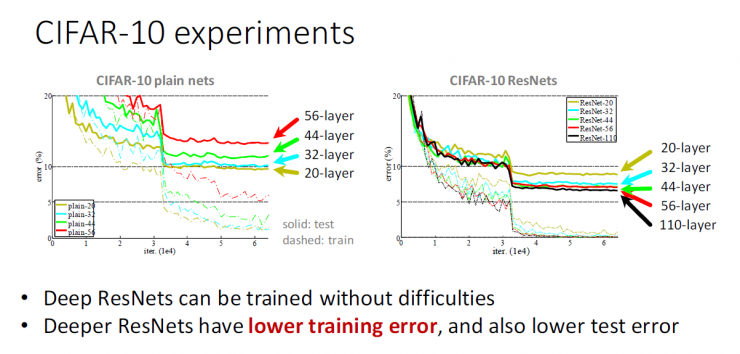
CIFAR-10 experiment
Deep residual network (ResNets) can be trained without any problems
Deep residual network (ResNets) has lower training error and test error

ImageNet experiment
Deep residual networks (ResNets) can be trained without any problems.
Deep residual network (ResNets) has lower training error and test error.
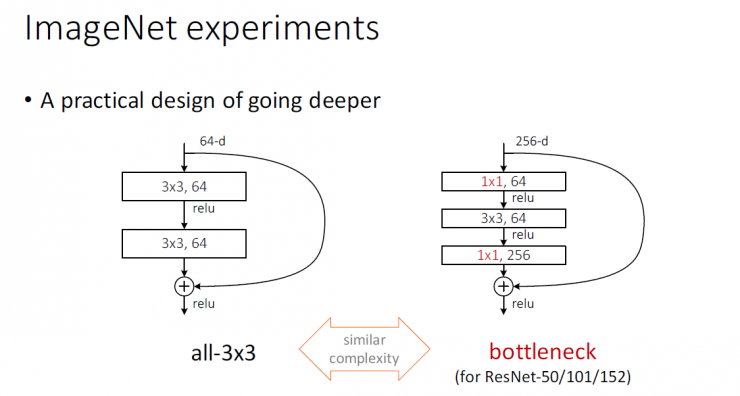
A step-by-step practical design plan
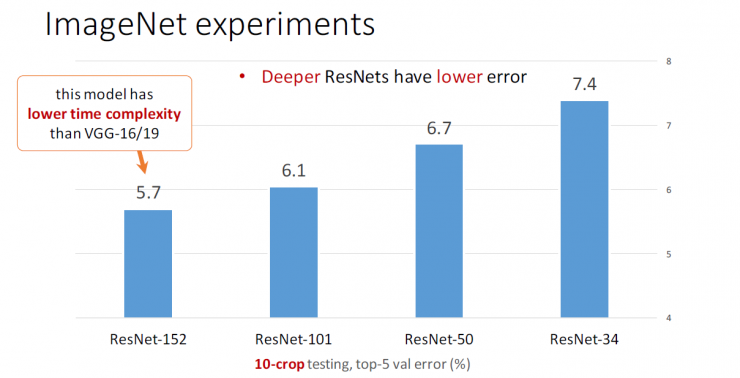
Deeper ResNets have lower errors
Compared with VGG-16/19, this model has lower time complexity .
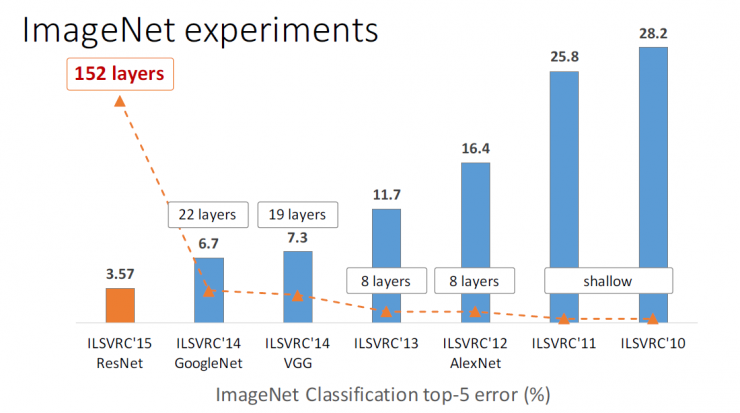
Image Network Classification Error Ranking Top 5 Network Models

discuss
Characterization, optimization, induction
Some problems with the learning depth model
Characterization ability
If you can find the best characterization method, you will have the ability to build a model to fit the training data.
If the resolution space of model A is the parent of B, the resolution of model A is higher.
Optimization ability
Finding the feasibility of the best characterization method
Not all models can be optimized very easily
Inductive ability
If the training data is fitted, what is the performance of the test?

How will ResNets solve these problems?
Characterization ability
Residual network does not have a direct advantage in model characterization (just implements duplicate parameterization)
However, the residual network allows for in-depth characterization of all models
Optimization ability
Residual network makes feed-forward/back-propagation algorithm very smooth
For the most part, the residual network makes it easier to optimize deeper models
Inductive ability
The Inheritance Problem in the Process of Learning Depth Model Without Residual Networks
However, deeper and thinner is a good induction
In addition, for a detailed introduction to the residual network, see Dr. He Kaiming 's best paper in 2016 CVPR - Deep Residual Learning for Image Recognition in Image Recognition :

In the paper, a deep-level residual learning framework was introduced to solve the accuracy reduction problem. We explicitly make these layers suitable for residual mapping instead of hoping that each stack layer fits directly into a required underlying mapping. Formally, H(x) is taken as the required basic mapping so that the stack's nonlinear layer fits another mapping F(x): = H(x)-x. The original mapping then translates into: F(x)+x. We assume that optimizing the remaining mappings is easier than optimizing the original unreferenced mappings. If identity mapping is optimal, then pushing the remaining mappings to zero is easier than adapting identity mappings with a bunch of nonlinear layers.
The formula F(x)+x can be implemented by a "fast connection" feed forward neural network. Quick links are one or more of those skipped. In our scenario, Quick Connect simply performs identity mapping and adds their output to the overlay's output. Identity shortcut joins neither generate additional parameters nor increase the complexity of calculations. With backpropagating SGD, the entire network can still be trained in an end-to-end fashion, and public databases (such as Caffe) can be easily used without modifiers.
We conducted a comprehensive experiment on ImageNet to show the accuracy degradation and evaluated our method. we discover:
(1) The particularly deep residual network is easy to optimize, but the corresponding "planar" network (ie, a simple stack layer) exhibits higher training error as the depth increases.
( 2) The deep residual network can achieve high accuracy while greatly increasing the depth, and the resulting result is essentially superior to the previous network.
Similar phenomena also appear in the CIFAR-10 set, which shows the difficulty of optimization, and our approach affects more than just a specific set of data. We have presented successful training models in more than 100 layers of data sets and explored more than 1,000 layers of models.
In the ImageNet hierarchical data set, we obtained very good results with extremely deep residual networks. The 152-layer residual network is the deepest network in ImageNet, and still has lower complexity than VGG network. Our integration has 3.57% of the top 5 errors in the ImageNet test set and achieved first place in the 2015 ILSVRC classification competition. This extremely deep statement also has excellent generalization performance in other recognition tasks, and led us to further win the first place: in the ILSVRC and COCO2015 contests, mageNet detection, ImageNet positioning, COCO detection, and COCO segmentation . This strong evidence shows that the remaining principles of learning are universal, and we expect it to apply to other visual and non-visual problems.
PS : This article was compiled by Lei Feng Network (search "Lei Feng Network" public number) and it was compiled without permission.
Via Kaiming He